

 28 904
28 904  Оставить комментарий
Оставить комментарий
 Сохранить статью:
Сохранить статью:
В статье рассказывается:
- Concurrent vs Parallel vs Async
- Многозадачность
- Проблемы планирования задач
- Общая память
-
 Пройди тест и узнай, какая сфера тебе подходит:
Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Здравствуйте!
Как только инженеры придумали многопроцессорные системы, перед программистами сразу встала проблема: как с наименьшими затратами обеспечить параллельное выполнение кода. И хотя с тех пор прошло немало времени, главные принципы не изменились.
В этом цикле статей я хочу рассказать о том, как многопоточное программирование реализовано в разных языках, и как их разработчики смогли облегчить жизнь программистам.
Но сначала мы поговорим об основах. Важное предупреждение: это очень поверхностная и обзорная статья. Если вам кажется, что в ней сказано недостаточно — вам не кажется. Подробности позже. Сейчас общее.
входят в ТОП-30 с доходом
от 210 000 ₽/мес

Скачивайте и используйте уже сегодня:


Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда

Подборка 50+ бесплатных нейросетей для упрощения работы и увеличения заработка
Только проверенные нейросети с доступом из России и свободным использованием
ТОП-100 площадок для поиска работы от GeekBrains
Список проверенных ресурсов реальных вакансий с доходом от 210 000 ₽
Concurrent vs Parallel vs Async
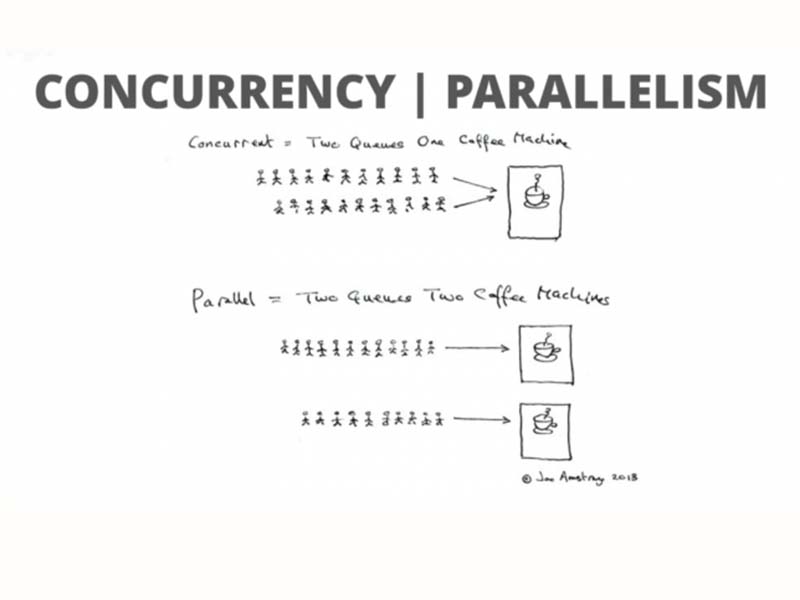
На Stackoverflow есть популярный вопрос: «чем concurrent отличается от parallel в контексте программирования?». Вот мое видение вопроса.
Concurrent — это постановка проблемы. Я хочу, чтобы некоторые части моего кода выполнялись независимо друг от друга, одновременно.
Parallel — это один из способов решения проблемы одновременности, когда задачи выполняются на отдельных процессорах или ядрах параллельно.
Другой способ решения этой проблемы — выполнение задач в одном потоке в режиме разделения времени: выполняем кусок одной задачи, потом кусок другой, и так далее. Для пользователя это выглядит так, будто задачи выполняются одновременно.
См. также: сопрограммы (coroutines)
Скажем, Erlang реализует сразу два подхода к одновременному выполнению задач: он запускает несколько планировщиков, каждый из которых работает на своем процессорном ядре, и распределяет между ними потоки виртуальной машины. Но так как потоков обычно гораздо больше, чем планировщиков, то каждый планировщик внутри себя реализует вытесняющую многозадачность на основе сокращений(reductions). При этом конкретный поток работает абсолютно, идеально синхронно со стороны кода. Я расскажу о планировщике Erlang в деталях в одной из следующих статей. Там все очень интересно.
Скачать файлAsync — вообще совершенно отдельная от многопоточности тема, потому что асинхронное выполнение кода возможно в одном потоке без concurrency. Пример — JavaScript: он однопоточный, он не реализует concurrency, и при этом вы можете отложить выполнение куска кода на потом с помощью петли событий. У нас в блоге есть подробный разбор того, как работает JavaScript.
Ради справедливости нужно заметить, что есть экспериментальные реализации многопоточного движка JavaScript, который реализует concurrency. Вот, взгляните: https://medium.com/@voodooattack/multi-threaded-javascript-introduction-faba95d3bd06
Многозадачность
Я выделяю два основных вида многозадачности.
Вытесняющая
Это то, как работают планировщики современных операционных систем: ОС сама решает, когда и сколько времени она даст каждому потоку, а мнением потока никто не интересуется. При этом для потока переключение контекста происходит незаметно.
Применительно к языкам программирования, вытесняющая многозадачность — когда управление задачами берет на себя виртуальная машина, а сами задачи не имеют возможности управлять переключением.
Такая многозадачность реализована в Erlang, Go и Haskell.
Кооперативная
Тут все наоборот: потоки сами передают управление другим потокам, когда захотят. В старых ОС были именно такие планировщики. Кооперативная многозадачность реализована во многих языках, например в Python, OCaml, Ruby, Node.js.
Проблема кооперативности очевидна: поскольку управление потоками по сути передается в руки программиста, появляется множество возможностей отстрелить ногу по самое колено.
на обучение «Разработчик» до 05 мая
Кроме того, есть еще невытесняющая многозадачность, но я отношу ее к краевому случаю кооперативной. По сути, это переключение задач по желанию пользователя. iOS-разработчики могут помнить, как было реализовано переключение между приложениями в первых версиях iOS: когда пользователь сворачивал приложение, ОС говорила ему: я собираюсь остановить твое выполнение, сохрани свое состояние. При повторном запуске приложения ОС передавала ему сохраненное состояние, и для пользователя это выглядело так, будто приложение продолжало работать с того же места, где было свернуто.
Проблемы планирования задач
Если вы хотите реализовать свой планировщик задач, перед вами встанут два главных вопроса: по какому принципу вы будете переключаться между задачами, и в каком порядке будете задачи выполнять?
Переключение контекста
У первой проблемы есть несколько возможных решений. Самое простое — просто подождать, пока задача закончится. Но что вы будете делать, если в одной из задач вдруг окажется бесконечный цикл? По такому принципу работает JavaScript, однако при достаточно долгом выполнении одной задачи вмешается уже сам браузер и предложит остановить обнаглевший скрипт.

Более сложные варианты — переключать задачи по времени выполнения, или по количеству вызовов функций (по сокращениям). Про сокращения мы еще поговорим позже.
Приоритеты
Теперь второй вопрос: как отсортировать очередь задач, чтобы всем досталось немного времени, и никто не обиделся? Ну, можно вообще не париться, и просто выполнять задачи по очереди: первый зашел, первый вышел (FIFO). Но в таком случае при постоянном притоке задач каждая задача будет вынуждена подождать, пока до нее дойдет очередь.
Можно случайным образом брать задачи из очереди, и при небольшом количестве задач эта стратегия себя оправдывает.
Наконец, можно реализовать систему приоритетов, как это сделано в планировщиках современных ОС.
Языки с реализованными планировщиками решают для себя эти вопросы по-разному, в зависимости от приоритетов разработчиков языка. Скажем, Erlang позиционируется как soft-realtime язык, поэтому он крайне агрессивно и часто переключает контекст, чтобы как можно быстрее дать отработать каждой задаче хотя бы частично.
 ТОП-100 площадок для поиска работы от GeekBrains
20 профессий 2023 года, с доходом от 150 000 рублей
Чек-лист «Как успешно пройти собеседование»
ТОП-100 площадок для поиска работы от GeekBrains
20 профессий 2023 года, с доходом от 150 000 рублей
Чек-лист «Как успешно пройти собеседование»
Общая память
Синхронизация доступа к данным — одна из первых вещей, с которыми столкнется человек, берущийся за многопоточное программирование в низкоуровневых языках. Скажем, C вообще не имеет встроенных примитивов для синхронизации доступа, и вам как минимум потребуется использовать POSIX Semaphores или написать свое решение. В Java есть уже некоторые полезные штуки, но вам все равно придется сперва разобраться в том, как они работают.
А сама проблема заключается в том, что в большинстве языков с неизолированными потоками два потока могут читать или писать в одну переменную, никого о том не предупреждая. Если не разруливать такие ситуации, можно легко получить неопределенное поведение программы.
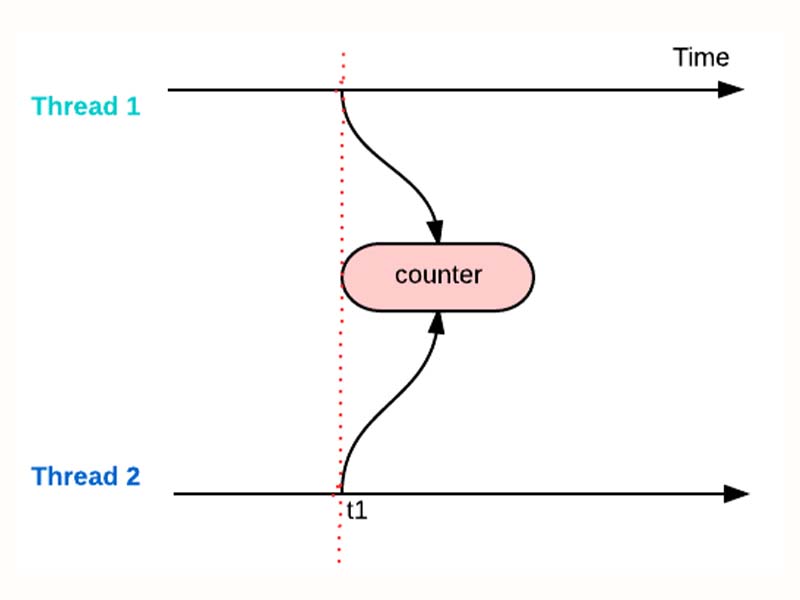
Для решения этой проблемы применяют блокировки, неблокирующий доступ (CAS) и некоторые особенности конкретных языков.
Блокировки
Блокировки работают очень просто: прежде чем писать в переменную, поток должен захватить семафор. Остальные потоки будут вынуждены ждать, пока семафор не освободится, и лишь потом один из других потоков снова захватит семафор, и так далее. Разумеется, это медленно работает, а также намертво блокирует ожидающие потоки. Кроме того, можно прекрасным образом написать код с взаимными блокировками.
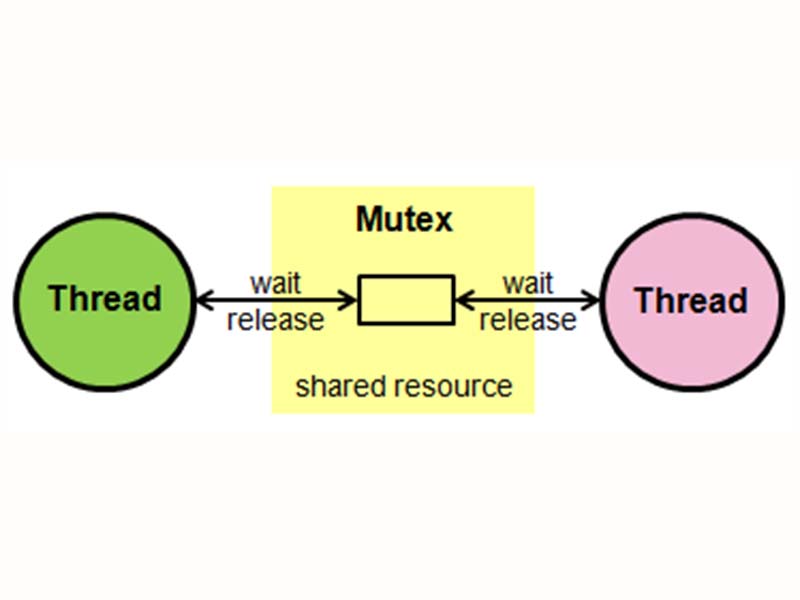
Краевой случай семафора — мьютекс, максимально упрощенный семафор. Главное в нем то, что только один поток в один момент времени может владеть мьютексом. Операционные системы часто имеют свои высокопроизводительные реализации мьютексов — фьютексы в Linux, FAST_MUTEX в Windows. Кроме того, в различных языках есть свои специализированные реализации мьютексов для особых задач.
Не-блокировки
Чтобы избежать части проблем, придумали неблокирующие реализации синхронизации. Одна из них — CAS, compare and set. Я оставлю ссылку, чтобы вы могли почитать о том, как это работает: https://ru.wikipedia.org/wiki/Сравнение_с_обменом. И вот еще вам небольшая презентация: slideshare.net/23derevo/nonblocking-synchronization
Наконец, есть еще один железобетонный способ избежать проблем с синхронизацией: давайте просто запретим потокам писать в общую память. Пусть у каждого потока будет своя куча, где он будет хранить свои данные, а если нужно обменяться информацией — пусть шлет сообщение другому потоку. Такая модель реализована в Go и Erlang, например.
Haskell первым реализовал еще один подход к проблеме синхронизации — STM, software transactional memory. По сути, это реализация транзакционного чтения-записи в общую память, аналогично тому, как устроены транзакции в базах данных. Подробнее можно почитать тут: https://ru.wikipedia.org/wiki/Программная_транзакционная_память
Итак, мы немного посмотрели о том, какие проблемы несет в себе многопоточное программирование и как их теоретически можно решить. В следующих статьях мы посмотрим, как с этими проблемами справляются разработчики разных языков программирования.










 Разберем 11 самых важных жизненных вопросов
Разберем 11 самых важных жизненных вопросов






